

编者按:本文内容由YouTube视频老周横眉转录,略有字词修改。
大家好,我是老周。我们先来看两张图。

第一张,这是世界最大的在线流媒体公司Netflix(奈飞)的全球业务版图。红色是他们覆盖的一百九十几个国家,黑色是不覆盖的四个国家:中国、俄罗斯、朝鲜和叙利亚。其实,在2022年以前,俄罗斯也是被覆盖的,是因为俄乌战争之后才停止的。
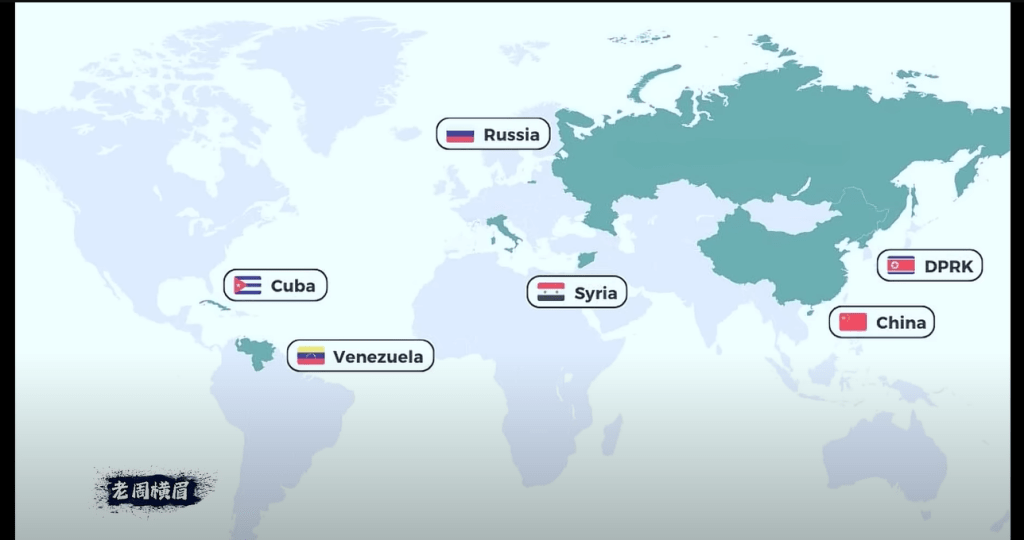
第二张图,这是全球最顶尖的人工智能ChatGPT能够使用和不能够使用的世界地图。深色是不能够使用的国家,基本还是那几个“好兄弟”,再加上伊朗、古巴和委内瑞拉。而古巴和委内瑞拉是自己封禁的,OpenAI自主不对其开放的国家其实只有四个:中国、俄罗斯、朝鲜和伊朗。
当然,这些也不算是什么新闻了。但今年六月份接连两个重磅消息,让我们再一次深深地感受到:中国与墙外的世界正在渐行渐远。
两周前,中国陆续有API开发者在社交媒体上表示,他们收到了来自ChatGPT母公司OpenAI官方的邮件通知。邮件表示,OpenAI自7月9日起将采取额外措施,禁止来自不在OpenAI支持的国家和地区名单上的开发者继续使用ChatGPT的API。这里指的“不支持的国家和地区名单”,就是刚才我们看到的这张图。
对技术领域不太熟悉的观众们可能觉得有点不太明白。你会觉得:中国本来不就一直都用不了ChatGPT吗?这个消息跟之前的有什么不同呢?没关系,老周接下来用大白话来给大家解释清楚了。
其实,我们一直都在说中国人用不了ChatGPT,但那只是普通用户无法直接使用。但其实还是有后门可以走的,那就是通过API接口集成到APP或网页上,让用户可以间接使用到ChatGPT。
要了解这个概念,我们首先要了解什么是API。API的全称是Application Program Interface,直接翻译过来就是“应用程序编程接口”。我们不需要去了解底层的技术,直接举例子大家就明白了。
比方说,你现在打车或者叫外卖的时候,打车软件和外卖软件里都是有地图的,对吧?用来展示你的行程或者司机目前的位置、骑手距离你还有多远等等。那么你想想,如果现在是你要新开一家外卖公司,当你在开发你公司的外卖APP时,难道你还得重新写一个庞大的地图程序吗?
肯定不是这么干的!因为市面上已经有现成的地图软件了,比如谷歌地图、高德地图等等。所以,这些外卖APP和打车APP其实只需要直接借用别人家的地图,然后给谷歌或高德支付使用费就可以了。
但问题来了:你要用人家的功能,人家不可能把自己的核心程序代码都给你吧?就算给你了,你要跟你自己的程序相结合,那也是非常耗时耗力的工作,还会有很多兼容的问题。所以,这些地图公司如果想要出售他们的地图服务,他们就会开发出一个API,也就是一个可以让别人直接使用他们程序的接口。
有了这个接口,外卖公司要使用高德地图时,完全不需要知道高德地图的程序到底是怎么运作的。他只需要把自己的APP跟这个接口连接起来就行了。
我们可以打这么一个比方:你家里的电器,比如电视、电冰箱和烤面包机,都需要电源来工作。为了连接到电源,你就需要将电器的插头插进墙上的电源插座,也就是接口。你不需要知道电源插座背后是怎么布线的,也不需要了解电流的具体工作原理,你只需要把插头接进电源接口里,电器就能工作了。这就是API的原理。
好了,那么我们回到原本的话题。OpenAI也为ChatGPT提供了这样的API接口,让所有想要使用他们功能的开发者和企业接入就能使用。当然,这是需要付费的。这就是为什么你在墙内可以下载到很多所谓的国产ChatGPT,还有很多自称是自主研发的人工智能大模型。其实,他们只不过是建了一个外壳,也就是你使用的时候看到的画面——输入界面啊、按钮啊什么的。但其实背后,他们就是接上了ChatGPT的API。
之前很多人还通过这种套壳方式赚了很多钱。除了套壳的以外,OpenAI API的用途是巨大的。国内很多企业和开发者利用ChatGPT的API开发出了各种各样的应用去满足不同市场和领域的需求,比如翻译APP,或输入几个重点就能自动生成PPT的应用,还有智能客服、陪孩子聊天和写作业的应用等等。这些应用背后,其实大部分都是通过接上了OpenAI的API接口去实现的。
其实,很多一般的企业和开发者,就连字节跳动和百度都被爆出使用OpenAI的API来训练自己的大模型。今年年初字节跳动就因为违反规定,被OpenAI封禁了他们的API账号。
但这一切自今年7月9号开始就全部都要结束了,因为ChatGPT的母公司OpenAI宣布,将重点禁止来自中国、俄罗斯、朝鲜和伊朗这些国家的开发者继续使用他们的API。
其实,这件事对于关注OpenAI动向的人来说,也不能说有多么的突然。因为今年已经有几次征兆了。
五个月以前,也就是今年的2月15号,OpenAI和大股东微软联合发布了一则声明,称他们发现了一些国家级的黑客团队正在使用他们的大模型来加强自己的网络攻击活动,并公布了他们封禁的五个账号,分别来自俄罗斯、朝鲜、伊朗和两个中国的账号——Chaco Typhoon和Selman Typhoon。
这里要明确,不是说这些账号企图入侵OpenAI,而是说他们企图通过API接口,利用OpenAI强大的人工智能来帮助增强他们自身的攻击力量。他们利用OpenAI的人工智能来干什么呢?开发破解网络安全的工具,检测敏感词和文章,制作钓鱼软件,开发监控人民的技术等等。
而OpenAI为了确保AI技术能够被安全和负责任地使用在为人类造福的活动当中,所以封禁了这些账号。OpenAI在报告中列出了这些账号的ID、他们所进行的活动记录、他们正在进行中的项目,以及OpenAI如何阻止他们的活动。这是一份非常详细的报告,证据确凿、铁证如山,所以根本没有看到来自墙内的任何官方反驳。
然后是今年的6月2号,OpenAI再次公开封禁了一批账号,原因是这些账号利用他们的人工智能在网上进行秘密的欺骗性活动。什么意思呢?就是利用OpenAI的人工智能工具在各种社交媒体上大量注册虚拟假账号,并通过发布虚假内容和虚假回复来操控舆论。这次被封禁的账号全部都来自四个国家:俄罗斯、伊朗、以色列,以及你猜到了——中国。
所以,各位,不要以为你现在网上看到的那些无脑粉红言论还跟以前一样都是五毛党,或者是在监狱里踩缝纫机的。其实现在很多都是通过人工智能创造出来的机器人账号。
对于上述情况,OpenAI同样公布了一份长达39页的PDF报告,非常详细,并且是完全公开透明的。跟往常一样,我视频里引用的数据来源和链接都会公开在视频结尾处和下方视频介绍里。有兴趣阅读这份报告的观众,看完视频之后可以去这些地方找到。
这是怎么说呢,真的非常丢脸。以前中共通过五毛党和监狱囚犯在网上给自己唱赞歌或辱骂批评政府的人,起码还是靠自己的力量。现在不要脸到一边说自己遥遥领先,一边利用别人的工具来干这些龌龊事了。
一位在墙内的人工智能从业者,也是大胆地说出了自己的心声:
“我不知道各位同行们什么感觉,我的感觉是羞愧、耻辱和愤怒。作为一个人工智能开发者,我羞愧于我自己和整个行业。一年多了,没有取得任何突破性的进展。我羞耻,是因为已经到今天了,我们在开发某些敏感技术的时候,还得依靠人家的人工智能。我愤怒,是因为那些天天喊着对标超越的人,你们到底做出什么产品来了?到底在干什么?为什么至今下到普通百姓,上到敏感项目,就是用不上你们发布的那些所谓‘超越’了的纯国产人工智能?”
OpenAI在本次全面封杀中、俄、朝、伊四位“好兄弟”之前,还做了另一个大动作。今年6月14号,OpenAI正式委任Paul Nakasone成为他们的董事会成员,并主管他们刚刚成立的安全与保障委员会。
Nakasone是一名顶级的网络攻防战专家,来头极大,简历相当震撼。他是退役的陆军四星上将,前美国国家安全局局长,曾担任美国网络安全司令部的主管。他在美军的各个级别担任过指挥和参谋职务,还曾在韩国、伊拉克、阿富汗的网络部队服役。
你看这个姓氏,Nakasone是一个相当普遍的日本姓氏。他其实是第二代美籍日本人。OpenAI在任命Nakasone的公告中表示,他将帮助保护OpenAI和ChatGPT免受来自日益复杂的不良行为者的威胁、滥用和攻击。
Nakasone上任的两周后,包括中国在内的几个国家就被全面禁止使用OpenAI的API接口了。OpenAI此举也可以说是迫不得已。面对来自中国和其他独裁国家的网络黑客攻击,以及那些一边说自己遥遥领先,一边却在利用美国科技来训练自己人工智能的这些国家,OpenAI只能一步步升级对这些国家的防范。
其实,我相信大部分使用OpenAI API的墙内企业和开发者,只是用来赚钱或者提高自己的生产力,并没有恶意。可惜,他们都成为了自己政府行为的牺牲品。
说到这里,我们就要想一想了:抖音里那些吃爱国饭的大V们,比如司马南和张公公之流,天天在吹嘘国产大模型已经如何先进,跟美国人工智能差距不大,甚至已经超越。那么,请问国内那么多的开发者和企业,甚至是国家对自己,为什么都要舍近求远,宁可克服重重障碍,也要使用人家的API,而不是去使用那些所谓符合社会主义价值观的国产大模型呢?
所以说啊,不怕不识货,就怕货比货。吹牛的人喜欢怎么吹嘘自己遥遥领先都好,最终用户的钱包和脚,才是最诚实的。
一年多的时间,人家的人工智能能力,从聊天到理解物理世界,再到多模态交互,处于光速进化中。人家的人工智能基础设施,从千卡到万卡,再到十万卡,算力成倍增长,能力越来越强,速度越来越快。而我们呢?除了一场场发布会、一个个口号、一次次股市套现,还有什么呢?有不服的朋友可以反驳我,那就请你告诉我,现在国内哪个人工智能大模型具备了和OpenAI同样的水平?哪个大模型能支持开发者做出同样的应用?有吗?有的话咱们可以公开测试一下。
除了OpenAI关上的这扇门,上个月让墙内那些希望拥抱文明和世界共同发展的人们所受到的打击,还不只是OpenAI封杀API这件事。
在6月初举办的苹果全球开发者大会当中,苹果重磅宣布了新一代苹果设备将带有一个集成性的个人智能系统,叫做 Apple Intelligence(苹果智能)。
发布会之后几天,苹果市值超越英伟达,重新夺回全球市值最高公司的宝座。通过Apple Intelligence,Siri将脱胎换骨,变成真正存在于你手机上的“贾维斯”。
下一代iPhone用户可以完全通过语音和自然语言操控手机,几乎所有苹果手机自带功能都将智能化。例如:
- 你的照片可以通过AI自动抹除多余部分;
- 你画的草图能自动变成完整图片;
- 编辑的短信可以自动生成表情包;
- 新一代计算器可以手写公式,手绘曲线也能识别。
最重要的一点是,苹果官宣了正式与OpenAI合作。当你让苹果手机完成复杂的智能任务时,手机会自动弹出调用GPT的选项。不需要跳转应用、无需注册、无需付费,最新的ChatGPT 4.0就能免费帮你完成。
问题来了,既然ChatGPT不对中国开放,中共也不允许中国人民使用“不学习社会主义价值观和习近平思想的人工智能”,那现在苹果手机负担了这些顶级人工智能,不就等于变相让中国人用上了吗?
万一有人拿着苹果手机问:
- “Siri,1989年6月4号中国发生了什么事?”
- “Siri,大跃进死了多少人?”
- “Siri,白纸运动是什么?”
- “Siri,习近平是不是一个独裁者?”
那该怎么办呢?
如同户晨风:“这种人严重违反直播规范啊!这种人我第一时间给他挂掉!”
所以结果就是,下一代iPhone中国版将不带有Apple Intelligence。
你现在去看任何国家的苹果官网,在iOS 18的介绍页面中,最显眼的就是对Apple Intelligence的介绍。但是,中国官网的同一个页面,下面什么都没有。当然了,苹果也说了,中国版iPhone的ChatGPT部分将由百度的文心一言来“平替”。
“平替”这个词就比较好笑。这就好比赛车的时候,你把法拉利换成了桑塔纳,然后说这是“平替”。只要你不是一个天天听爱国大V在抖音上胡吹的,任何一位真正使用过ChatGPT和文心一言的人,甚至只需要看过任何专业对比测试或演示视频的,都知道ChatGPT是真正的人工智能,而文心一言顶多只能算是一个没有广告的百度罢了。
ChatGPT 4.0目前已经进化到可以打开摄像头,跟用户实时对话。他能够感知到与他说话的人的情绪,自己的说话也是带情绪的。现在跟ChatGPT对话,充满了停顿、打断、感叹等情绪反应,就像跟一个真实的人面对面交流一样。
我们再来看看目前中国的进展。就在几天前,7月4号到6号,2024世界人工智能大会在上海举办。一个把世界上所有最尖端人工智能大模型都禁用的国家,却搞起了世界人工智能大会,本身就是非常滑稽的一件事。这就好比伊朗搞了一个“吃猪肉鉴赏大会”一样,或者是宦官举办了一场“AV鉴赏大会”。
所以,以后中国人花同样的价钱买一个苹果手机,得到的却是一个缺斤少两、与墙外世界所有人的苹果手机完全不同的东西。
因此有人说,从下一代iPhone开始,中国将与世界分道扬镳。但其实,中国与世界分道扬镳的这条路,已经开始了好几年了:
- 从战狼外交开始;
- 从煽动国民仇日恨美开始;
- 从支持俄罗斯的侵略战争开始;
- 从成为世界唯一承认塔利班政权的国家开始。
处处与普世价值观背道而驰,夜郎自大,到处树敌。
其实,墙内那些真正在搞人工智能的大佬们最清楚中国人工智能与美国的差距究竟有多大。他们只是嘴硬而已。在认清了底层的通用大模型是永远不可能追上美国的时候,现在开始说什么搞通用模型没有用,搞人工智能应用才是正确的方向。你听听百度李彦宏说的这段话:
“没有应用光有一个基础模型,不管是开源还是闭源,一文不值。”
他说的是什么反智的话?没有应用的基础大模型一文不值?这就好比说没有外卖APP的智能手机一文不值,没有安装游戏软件的电脑芯片和显卡一文不值。太可笑了!
但李彦宏也是迫不得已,只是嘴硬地想找回点面子。但他这么说,其实已经很明显地告诉大家了:文心一言和国内的通用大模型已经走不通了。
走不通就走不通嘛,可以虚心一点,而不是在那里继续吹牛。这就是中国这几年来“遥遥领先”、夜郎自大风气的根本问题:永远不肯承认自己的落后,打肿脸充胖子。
1978年10月,邓小平访问日本的最后一天,召开了记者会。他这样说:
“首先要承认我们落后。这个自己面孔长得本来不漂亮,要做一个漂亮的人不行。”
但现在呢,政府和行业大佬带头天天在新闻联播和网上吹牛逼,然后吃爱国饭的大V们在抖音上高喊“遥遥领先”。
U型索门的热血沸腾,一边失业在家啃老大半年了,一边在网上敲键盘高呼“中国已经是世界第一”。这就是现在中国的大环境。
这时可能有一些温和派要说了:“国产大模型虽然比起老美的有点差距,但我用手机又不是为了发射导弹,差不多得了。”但就算你相信国产人工智能的技术,你相信它的商业伦理和道德吗?
百度臭名昭著的魏则西事件,很多人应该还记得吧?
2016年,一名叫魏则西的大学生因为患有罕见的滑膜肉瘤,在百度上搜索治疗方法时误信了虚假广告,选择到武警北京二院进行未经审批且效果未经确认的治疗方法,最终导致耽误治疗而去世。
事件曝光后,引发了中国网民对百度竞价排名广告模式的集体讨伐,尤其是他们那铺天盖地的莆田医院广告。
但你今天回过头来看,百度最终并没有受到什么惩罚。在谷歌退出中国市场之后,它一家独大,这些年来它的行为模式完全没有任何改变。不论你搜索什么,出来的都是铺天盖地的广告。
就是这样的一家垃圾公司做出来的东西,即将和所有中国的苹果手机深入绑定。
本来中国的局域网和世界的互联网就已经像是两个世界了。比如,中国人去到国外,当大家都在使用谷歌地图时,却发现自己用不了。
中国人在国外,只要不是用酒店里的WiFi,而是用中国移动或中国电信的漫游网络,就无法使用谷歌、推特、WhatsApp这些墙外世界几乎人人都在使用的东西。
当然,我知道有人会说:“为什么一定要用西方的东西呢?我们中国人有自己的微信、微博、百度,都很好用,不需要你们的东西。”
首先,我理解,没问题。中国人当然可以用自己的东西。我在上海生活了15年,我也觉得微信、支付宝、大众点评等非常好用。我个人认为比WhatsApp和谷歌地图还好用,但“自己选择用什么不用什么”和“被强制不能用什么”是两码事。
比如,外国人如果来中国旅游,入乡随俗,当然也必须下载支付宝和滴滴打车,否则寸步难行。这都没问题,他们需要使用中国软件时就使用。
但中国人去到国外,当他们想要使用谷歌时,如果不通过违反中国法律的翻墙软件,就无法使用。回国之后,谨慎一点的,还要先把这些翻墙软件删掉,避免惹上麻烦。
连获取信息的自由都需要违法才能实现,这就是区别。这就是中国人与世界的隔阂。
接下来,人工智能将进一步扩大中国人与墙外世界的距离。
撇开技术本身不谈,中国的人工智能和世界的人工智能已经开始呈现出不同的特性。使用中文数据、中文信息进行训练的国产大模型,倾向于直接给出复制粘贴的答案,在推理和分析方面的表现非常弱。
这跟中国的文化特性有着相关性。因为中式教育更注重直接给答案,而不是分析和推理。通过大数据训练出来的人工智能,就像“一方水土养一方人”,在什么样的环境下训练,就会长成对应的样子。
几个月前,我在另一期关于中国人工智能的热门视频里已经说得很透彻:中国人工智能发展的最大障碍并不是美国对高端芯片的封锁,也不是人才,而是在一个没有言论自由和学术讨论自由的大环境下,中国严重缺乏可以用来训练大模型的高质量数据。
当时我说了一句:“垃圾数据训练出来的就是垃圾人工智能。”
其实,我真的蛮同情那些想要在中国认真研发通用大模型的人工智能从业者的。本来开发通用大模型已经是一件够艰难的事了,可是墙内的人工智能开发者还要攻克另一个难题:
如何研发一个能够自我学习的高智商智能体,同时又能让它不要乱讲话,不要根据事实和逻辑来自由表达?
这个难度太大了!墙内人工智能从业者真的太难了。在硬件已经有瓶颈的情况下,还要面对垃圾数据,还得强迫国产人工智能必须符合特色社会主义价值观。这就好比在一场赛跑中,本来就已经瘸了一条腿的人,眼睛还被政府蒙上了。朝着错误的方向前进,你再努力也是没有用的。
所以,我对中国大模型的发展前景是完全不乐观的。当然了,事实上,能够发展通用大模型的国家也没有几个。但区别在于,别的国家没有防火墙,也不搞战狼外交怼天怼地。
所以,他们的人民并不需要自己的国家自主研发,也能用上ChatGPT和Apple Intelligence。
逐渐的,中国将成为人工智能的一座孤岛。岛主振臂一呼:“我们遥遥领先,世界第一!”岛民们高喊:“万岁万岁万万岁!”却浑然不知,自己已经与世界文明渐行渐远。





Leave a comment